Having worked as a software engineer since 2012, I’ve gained experience across various domains including WordPress, Laravel, Ruby on Rails, backend, and frontend development. This year, I embarked on a new and exciting challenge as a backend software engineer at a prominent South American tech company, collaborating with a team of highly experienced professionals. The project, centered around a “feature store”—a concept new to me before joining—has presented novel challenges.
For those unfamiliar with feature stores, let’s first clarify what a feature is. A feature is a characteristic that describes an object, typically the subject of your study. These features are then utilized to train machine learning models or to make predictions based on them.
Feature engineering in machine learning is a crucial step for the success of the entire process. For me, coming from the backend, the “feature store” is a fascinating component. It functions as a central data API for ML, needing to serve features with very low latency for real-time predictions (like a cache) and, at the same time, provide large volumes of historical data for model training (like a data warehouse). The real challenge lies in building and maintaining data pipelines (ETLs) that feed this store reliably and consistently. This is Data Engineering in practice.
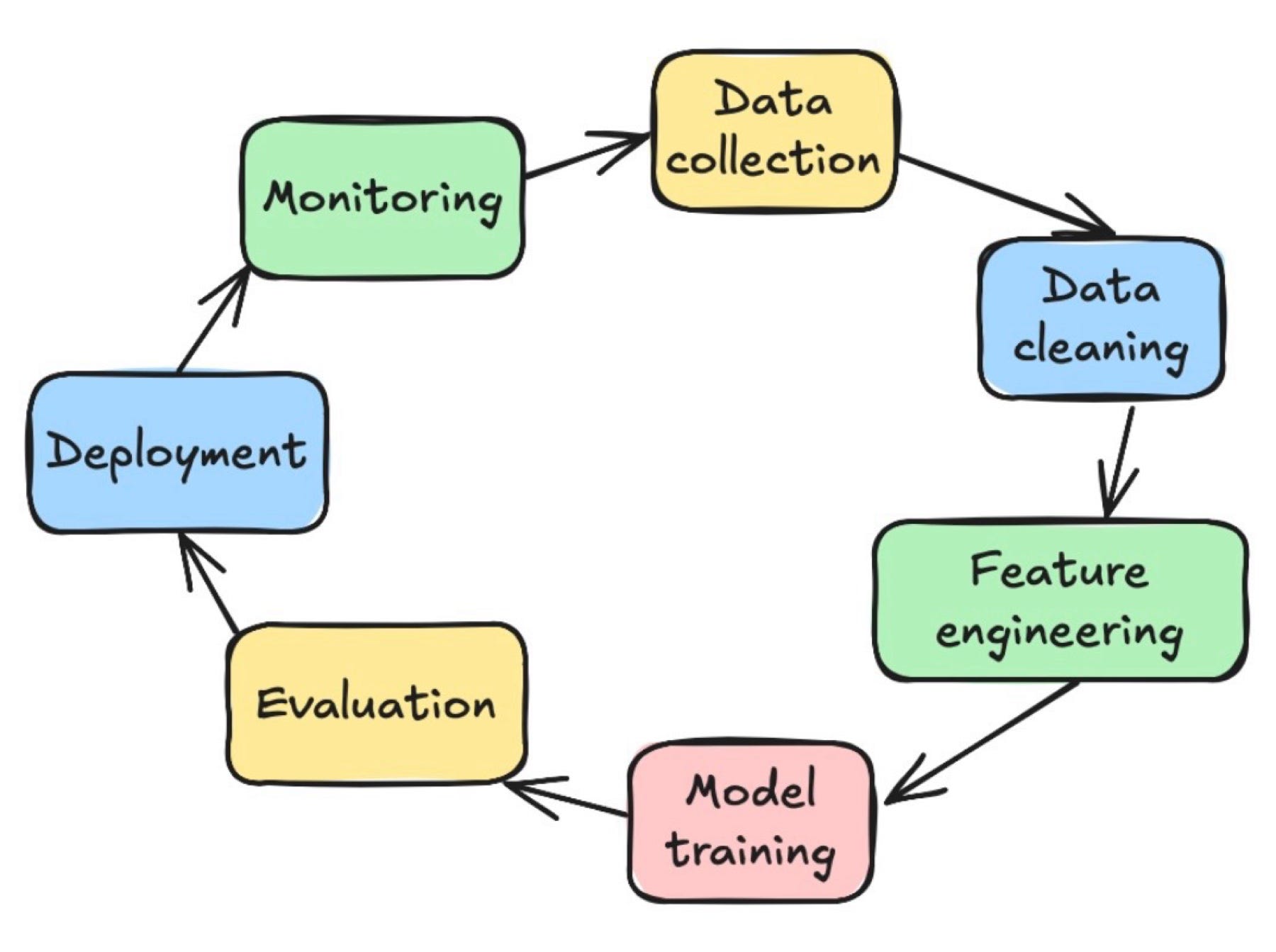
Source: Towards Data Science - Every Step of the Machine Learning Life Cycle Simply Explained
This exposure and the motivation to deepen my understanding of data engineering have inspired me to initiate a personal project focused on a data engineering career transition. To further this goal, I recently enrolled in a postgraduate program with a strong foundation in statistics. I’m thoroughly enjoying this course and am optimistic about the growing market for data engineering, a trend evident in Google’s search data.
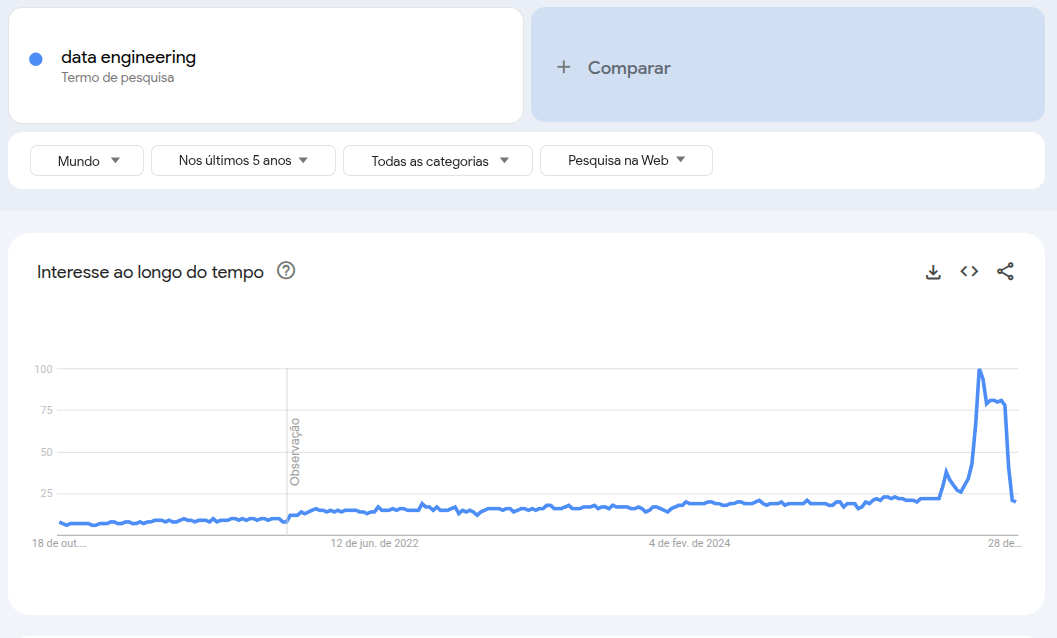
My pursuit of a data science analytics course, grounded in statistical principles, stems from a desire to comprehend the entire data science ecosystem. My goal is to specialize in data engineering, and understanding the broader field, including its statistical foundations, is crucial for this. In an era where large language models are increasingly capable of generating code, a solid knowledge base, particularly in statistics, becomes even more essential.
Statistical thinking has offered surprising insights, such as methods to enhance presentations and critical analysis skills. Furthermore, I’ve observed striking parallels between software engineering and data science learning, particularly in their foundational elements. Just as algorithms and data structures were fundamental when I began learning software development, they form the bedrock of many data science concepts, like trees.
Watch the commercial here: Schlitz vs Michelob - Super Bowl XV 1981
This commercial, cited in a renowned statistical book by Charles Wheelan, perfectly illustrates how statistics can be both entertaining and crucial.